
The Road to 1 Tbps

Serving free adult content that is coveted by billions of people on the Internet necessitates delivery without interruption (QoS) and mindfulness of the smallest of details in user experience (QoE). This new engineering blog aims to give transparency with respect to challenges faced by the Chaturbate crew and tells an evolution story.
Background
Live streaming delivered by either HTTPS or RTMP works over the Transport layer using TCP and as such furnishes a reliable service in the sense that it does not degrade picture frames or sound quality by network impairments such as high RTT, packet reordering, low available bandwidth, or packet loss. However, user QoE is adversely affected by these degradations in the form of rebuffering events and frame drops. A significant contributing factor of Chaturbate user frustration is the frequency of these rebuffering and reconnection events. By transcoding and imposing proper rate-adaption or playback buffering, the Chaturbate video player is typically able to adapt to above-average variations in throughput by stepping down to a more suitable lower bitrate rendition.
Wielding a transport mechanism that traverses firewalls and NAT with ease, the objective is then to provide the connecting broadcaster and the viewing client with network pathways that have minimal opportunities for packet loss. This content delivery optimization is commonly referred to as a Content Delivery Network (CDN), and Chaturbate's infrastructure has grown to the extent that it now consists of more than 20 self-managed points of presence (PoP) that each stream between 60 and 200 Gbps. Chaturbate PoPs are strategically located around the globe with route shortening from over 180 last-mile PoPs on the Cloudflare Spectrum network.
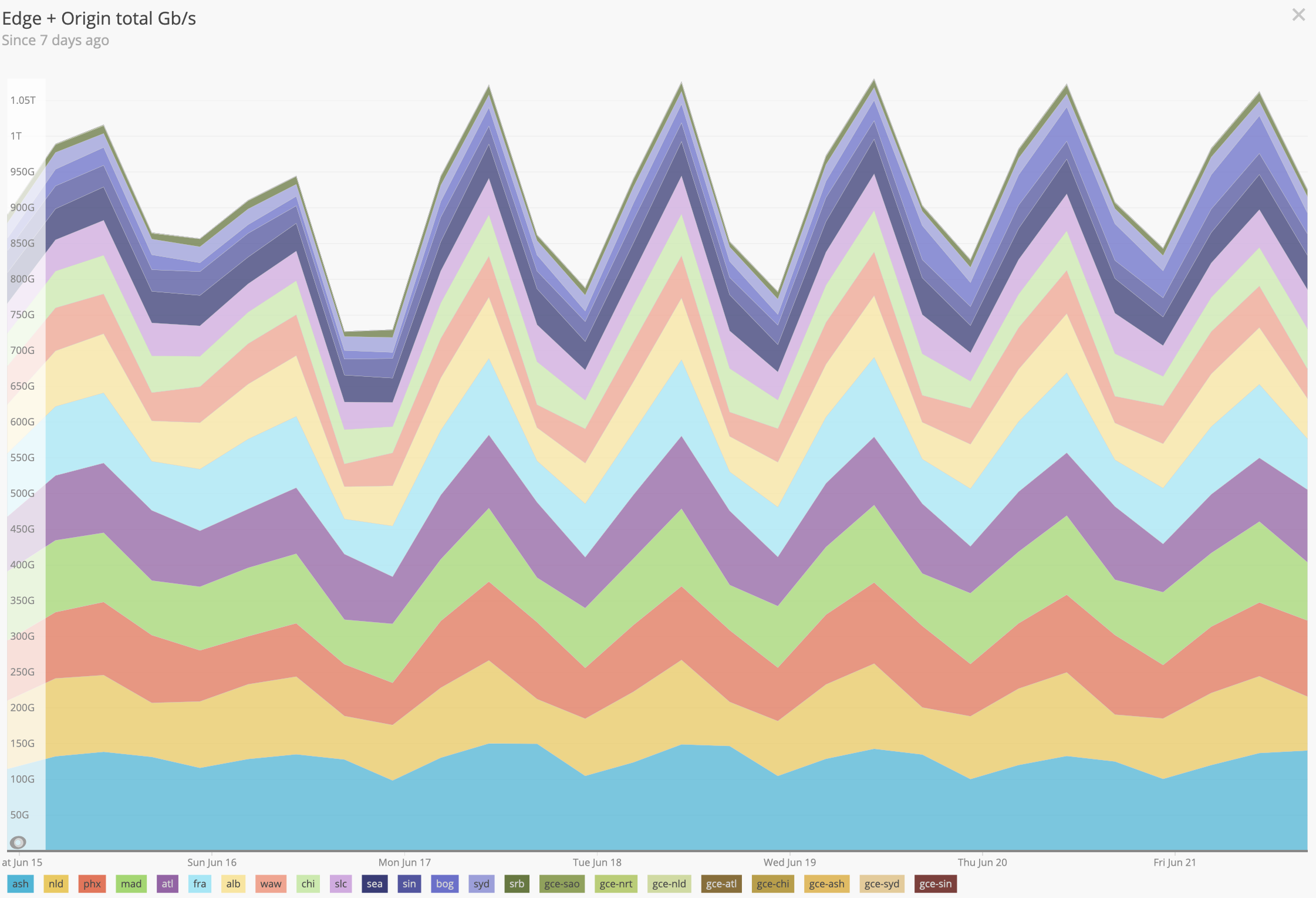
Another technological advancement that had an impact on delivering Chaturbate content came in late 2016, when Google developed a new congestion-based flow control algorithm for TCP called Bottleneck Bandwidth and Round-trip propagation time (BBR). Having been deployed across YouTube with a measured throughput increase of 4% globally, Chaturbate switched over all of its servers to Linux kernel 4.10+ in 2018 to improve inter-node throughput and congestion control.
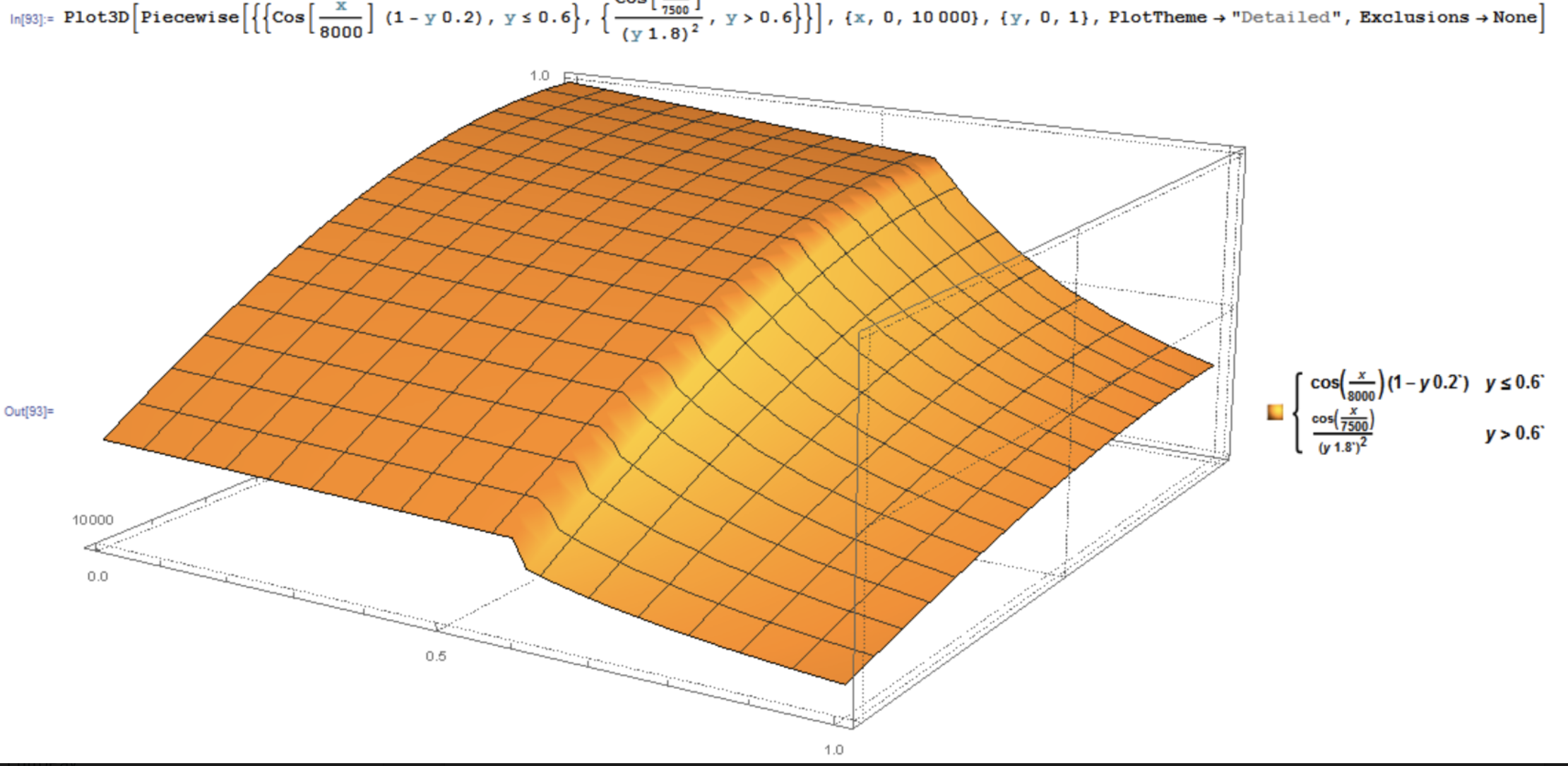
This year, Chaturbate is expanding with dual 100Gbps connectivity to each of São Paulo, Tokyo, Milan, Miami, and a second location in Phoenix. ISP peers are selected based on the source AS distribution analyses for broadcasters and viewers. Capacity is reserved in each region to adjust for variations in global load balancing anomalies including sudden bursts (attacks or legitimate) or drops. If one region goes dark or suffers from too much traffic, the Chaturbate application layer compensates for this automatically since the traffic distribution function is multivariate in region load, server load, geographic distance, and the number of streams. Additionally, limits are placed on the max load and room/stream counts per region and per server. After some experimenting, and considering the max distance between any two of our PoPs is ~8,000 miles, server weights taper according to the piecewise smooth function:
All regions now average ~30% load, which is defined as a function of GPU utilization of the 2-4 GPUs in the server, CPU utilization of the 24-48 cores per server, user count, and TCP stack load. Let's explore what makes up the load and how we counteract the demand with specialized hardware.
Transcoding
Chaturbate takes content that has been compressed and encoded by the broadcaster's end device connected to a webcam- typically a computer running an RTMP external encoder sending in H.264 4K or 1080P CBR video and AAC audio– and decodes it in order to simultaneously create a set of time-aligned video streams each with a different bitrate and frame size. This manipulation called transcoding is a must for making the multimedia content available and playable to the most clients and varieties of networks possible. Viewers that typically would not have sufficient bandwidth to view a 1080P stream at 30FPS would buffer constantly as they wait for the packets to arrive if a lower transcoded rendition were not available.
Chaturbate transcodes all streams and does not put a limit on incoming video bandwidth. Some other live streaming platforms may limit you based on popularity or ingress specifications like 1080P max throughput 6Mbps. I won't name them!
The process of transcoding takes a heavy toll on processing power; Chaturbate continues to invest in expanding to new locations with more Nvidia Tesla P100 (pre-2019) and Nvidia T4 GPUs (2019+) in origin video servers. Each server has 4 GPUs for NVENC api accelerated encoding to encode H.264 video faster and with less power consumption than CUDA-based or CPU-based encoding.

Looking forward, the mobile broadcasting framework that was implemented recently provides a good foundation for transitioning the broadcast page on Chaturbate away from Adobe Flash and towards WebRTC ingestion to the origin servers by default. WebRTC also allows for processing with a variety of additional codecs like VP8, VP9, and H.265. We are looking forward to supporting more ingest codecs as we grow our hardware support for them via NVENC and run them through sufficient testing to ensure stream and server stability.
On the output/viewing side of things, delivery of multimedia data in the form of chunks over HTTP is convenient and supported nearly everywhere without having to load a power-hungry dinosaur of a plugin (aka Flash). It lends itself to caching and proxying with Layer 7 tools like Nginx, and it is friendly with firewall and NAT traversal. HTTP allows for Transport Layer Security (TLS) with new cipher suites such as those provided in TLS 1.3 and even later quantum-safe cryptography when it becomes more prevalent. Scale out with HTTP multimedia delivery is also easier as the edge servers are basically webservers with software like Nginx on them. N.b., a negative of chunked live streaming is the delay as chunks are aligned to keyframes and sized to 1-2 seconds of duration with a minimum of 3 chunks per playlist. Chaturbate is keenly aware of this, having already reduced chunks to an average of ~1.5 seconds duration, and is currently implementing Low-Latency HTTP Live Streaming (LHLS) with fMP4 CMAF "micro" chunks that should keep final latency in the 2-4 second range. Transcoding accounts for a second or more of that duration.
Early Days
The early days of 2011 were dicey, starting with a single Dell PowerEdge R510 workhorse with 2 x Intel 10Gbps NICs, Intel X5672 at 16 cores, and 6399 MIPS/core (for a total of 102384 MIPS). The software at the time was heavily threaded with Native POSIX Threads (NPTL) using up a lot of CPU time and loading up all cores with computation for encode/decode. Transcoding was not added until mid-2017, so these early days were fairly simple in terms of the hardware requirements: keep adding more Dells. CapEx in the first year was minimized by consolidating as many daemons/services on the hardware as possible.
Distributed Denial of Service & Other Setbacks
subnets that were new sources of pornography were targets of daily Distributed Denial of Service attacks (DDoS).
Early on we also faced setbacks with cyber attacks, noticing that subnets that were new sources of pornography were targets of daily Distributed Denial of Service attacks (DDoS). Malicious traffic can come from many vectors– I didn't want to go down the path of pointing fingers as there is no empirical evidence with distributed attacks. It's better to be prepared and act quickly to squash any business impact. To counteract these attacks before our various encounters with BGP routed protection service providers like Prolexic, Black Lotus, Layer(3), etc., each video server had two small subnets configured. Linux rt_tables was utilized to implement connectivity for the origin nodes such that a null route of one subnet would not adversely affect service as a whole. It also allowed for utilizing two 10Gbps links on a server without the use of traditional link aggregation.
Because video streams produce high throughput north of a gigabit for a small stream count, mitigation occurred at a high enough level to not saturate any hardware filters or mitigation devices. Broadcasters were configured to send their stream to a random origin server like origin1. Using Round Robin DNS with a low TTL like 60 seconds, 2 more child nodes were configured as the "a-side" and "b-side": origin1-a configured with one /28 subnet and origin1-b configured with a different /28 subnet.
origin1 60 IN A origin1-a-ip
60 IN A origin1-b-ip
rt_tables was configured with Linux ip routing to send traffic through the gateway and interface matching the ingress traffic:
# NOTE: These IPs have been modified to private ranges
echo "1 first" >> /etc/iproute2/rt_tables
echo "2 second" >> /etc/iproute2/rt_tables
#P1_NET = 192.168.203.160/28
#IF1 = eth0
#IP1 = 192.168.203.165
#T1 = first
#P1 = 192.168.203.161
#P2_NET = 192.168.225.160/28
#IF2 = eth1
#IP2 = 192.168.225.165
#T2 = second
#P2 = 192.168.225.161
ip route add 192.168.203.160/28 dev eth0 src 192.168.203.165 table first
ip route add default via 192.168.203.161 table first
ip route add 192.168.225.160/28 dev eth1 src 192.168.225.165 table second
ip route add default via 192.168.225.161 table second
ip route add 192.168.203.160/28 dev eth0 src 192.168.203.165
ip route add 192.168.225.160/28 dev eth1 src 192.168.225.165
ip route default via 192.168.203.161
ip rule add from 192.168.203.165 table first
ip rule add from 192.168.225.165 table second
ip route flush cache
In the event of a DDoS or attack on one interface, the affected side could be safely null routed with the end user having to just refresh the client to re-connect to the same server and pick up state where last left off. This worked quite well for the first few years where the attacks were frequent, but as the infrastructure grew, the best solution for video streaming came in the form of expanding to more geographic locations and distributing the bandwidth outward.
System Design
Chaturbate chose the Open Compute (OCP) hardware platform to scale with flexible, open, and energy/space efficient guidelines that can be met with a variety of hardware vendors. Public cloud does not allow flexibility in choosing network peers or give many options with respect to GPU allocation. Large batch requests for GPU resources will take take time if the cloud provider does not have the assets available. The costs for bandwidth are prohibitively high in the public cloud, as we see providers such as Netflix building out their OpenConnect video streaming system in data centers worldwide, as well as Dropbox moving out of the public cloud into their own hosted datacenters.
Chaturbate has a mixture of microservices for site features like emoticon handling, hashtag population, serving JPEG streams and room thumbnails, making recommendations, populating tube feeds, and managing state of rooms worldwide to all datacenters. Distributed design, wherein teams can develop and deploy their own product without committee approvals keeps code deployment flowing quickly and compartmentalizes metrics collection and feedback for proper analysis and improvements.
Typical OCP Rack
A typical OCP rack as purchased from a vendor will come pre-cabled and ready to plug in to data center power feeds. The procedure is to wheel the rack into position, connect the power feeds (typically 400V 3PH 60A x 2 or 208V 3PH 30A x 4 feeds on disparate power circuits), verify 4G out-of-bands connectivity to a serial server at the top of the rack, and then turn up the BGP peering on the cumulus spine switches in the rack. The cloud servers are then powered up and will join the rest of the global cluster mesh using PostgreSQL-BDR over IPSec with OpenVPN to do some low-traffic inventory management for xCAT and to synchronize netboot install images.
Only 3 servers in the rack used for the VMs that power the IPSec and local xCAT service node have disks. Everything else is diskless and netboots off an image from the xCAT service node. The image is typically a heavily stripped CentOS 7 minimal image with some custom postscripts and a custom kernel. These postscripts invoke Ansible to configure the server to its appropriate purpose. The server will do a pull of the playbook from version control, and then apply the playbook to itself, locally after boot effectively doing updates and applying all changes to the base image and mounting appropriate mounts.
Having diskless servers servers is great for security; by rebooting a node, the server is immediately reset back to the stripped image and the playbook gets re-applied with fresh updates. Configuration management is version controlled with peer review and large batches of servers get booted in seconds.
Furthermore, system configurations for all servers are stored in git and PostgreSQL, each of which allow for incremental backups and quick restoration to new facilities. The same Ansible playbooks that run on each boot could get applied to a new VM in AWS or on a metal server in a new facility. If 1000 edge servers are needed in Eastern Europe, it is possible to configure them all in parallel with Ansible or configure one base image with the play, and then boot that base image 1000 times.
Network Design
Every switch must have a pair for high availability. Multi-Chassis Link Aggregation (MLAG) is utilized in a spine-leaf topology and the configuration for all switches are applied with Ansible and version controlled with peer review. Changes to infrastructure configuration go through the typical DevOps pipeline requiring review, change control, quality testing, deployment, and post review.
Spine switches are typically 32-port 100Gbps hardware running Cumulus Linux. The Spines will BGP with upstream. Leaf switches are 48-port 10Gbps with 100Gbps uplinks or 48-port 25-Gbps with 100Gbps uplinks. Servers are dual-connected to each top-of-rack leaf switch in CLAG bonding. From the server to the core routers there is a secondary path for a packet in the event of failure and to load balance.